
La IA como Chatt es posible gracias al uso indiscriminalmente del contenido en línea. Cloudflare acaba de decir que había terminado – La nación

El Big IAS, que usamos todos los días como GPT, Géminis, Claude, Confusión y Sociedad, existen y pueden hacer lo que hacen, lo que hacen, en gran medida el contenido disponible en Internet. Empresas como OpenAI, Google y Anthrope para mencionar que algunos han seguido (y perseguen) la Web en busca de contenido que responda las preguntas del usuario.
Y lo hacen, a menos que haya ciertos acuerdos sin tener en cuenta los creadores de este contenido más allá de una conexión. Es una práctica cuestionada por el nacimiento de esta tecnología. Artículo del blog, Wikipedia, libros, contenido generado por el usuario, datos personales. Los rastreadores, estos bots automatizados, no dejan nada atrás y hoy Cloudflare dijo que ha terminado
A partir de hoy, CloudFlare se bloqueará de forma predeterminada raspador De la IA, algo que tiene más efectos en lo que parece. Comencemos por el principio.
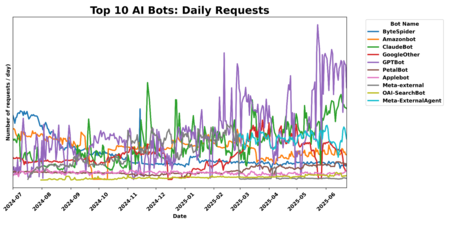
Rastreador web. Esta tecnología no es nueva y, de hecho, las bases en las que se basa Internet (la búsqueda en la web) está disponible. Seguro que es familiar “Google Spider“, La oferta que sigue todo el sitio web en busca de contenido para el índice y el usuario. Es solo uno de los miles y miles que existen y generan el 30% de todos los datos de tráfico en todo el mundo.
Esta tecnología era capital para formar Internet que conocemos y que la relación con los generadores de contenido era simbiótica. El clic del clic nació: el Creador genera un contenido, Google Lo Indexa, el usuario lo encuentra a través de Google, Google genera ingresos con la publicidad del motor de búsqueda, el Creador recibe tráfico gratuito y genera gracias a la publicidad, los socios, etc.
La película es muy diferente con la IA.
Datos. Los modelos de IA necesitan información para alimentar, ser capacitados y responder preguntas. Para este propósito, las grandes empresas, de las cuales todos sabemos que está persiguiendo la web, lo han extraído y utilizado para desarrollar tecnologías como Chatt. ¿Cuál es el problema? Este contenido podría estar protegido por los derechos de autor, lo que causó el New York Times por la misma razón para exigir OpenAai, ya que las compañías de IA tuvieron que firmar con los medios para acceder a su contenido.
IAS conectado. AI desarrollado y, como se esperaba, Estaba conectado a Internet. No solo dio respuestas basadas en datos de capacitación finitos, sino que también podría conectarse a la red para buscar la respuesta en tiempo real (o casi en tiempo real) para la respuesta en los medios de comunicación, los blogs y los sitios en línea. El usuario ya no tenía que hacer clic en un enlace. La IA estaba buscando, analizó y generó la respuesta e hizo tráfico en los medios y blogs.
El usuario ya no accede al contenido original y no hace clic en los enlaces. En cambio, consume un producto derivado que es generado por AI
Para esta tecnología, el AI Crawler o lo que es lo mismo se administra la vida: el rastreador IA. Son la digievolución de los bots que dan forma a Internet que conocemos. Entre ellos están OpenAai Gptbot, meta-externalagenes meta, Claudebot de antrópico O-bytespider de bytedance. La relación simbiótica comienza a empeorar con ellos, ya que el usuario ya no accede al contenido original y no hace clic. En cambio, consume un producto derivado generado por IA.
El ejemplo más grande: Nuevas vistas anteriores creadas con AI Esto se muestra cada vez que realiza una búsqueda.
Establezca el freno … o no, solo soy un .txt. ¿Cómo resuelvo esta persecución indiscriminada e independientemente? La primera propuesta fue actualizar el archivo robots.txt para mostrar los bots que no pueden extraer el contenido de un sitio web. Sin embargo, este archivo y uno de los recursos más utilizados para administrar la actividad de los bots tienen un pequeño problema: su cumplimiento es voluntario. Las empresas de IA pueden seguir las instrucciones o ignorar y extraer el contenido.
Además, puede suceder que tocemos lo que no deberíamos y que nuestro sitio web de Google desaparezca. Cada sitio web que desee estar en Google debe permitir que Googlebot, su araña, muestre los bots que no pueden extraer el contenido de un sitio web. Este archivo es uno de los recursos más comunes para administrar la actividad de los bots, pero tiene un pequeño problema: su cumplimiento es voluntario. Las empresas de IA pueden seguir las instrucciones o ignorar y extraer el contenido.
Se planta la mancha de nubes. Llegamos al último anuncio de Cloudflare. La plataforma (en la que depende de Internet mediano) ha anunciado que el bloqueo del Crawler de IA estará activo a partir de hoy. Para este propósito, CloudFlare ofrece administración directa de robots.txt para evitar problemas como lo anterior. La clave es, por supuesto, que CloudFlare es responsable de mantener los bloqueos actualizados de acuerdo con el Panorama IA. Esto se activa por defecto, pero es voluntario y puede desactivar por completo en los ajustes.
Para pagar. CloudFlares es una propuesta diferente Pago por rastreo. Dado que la IA todavía necesita acceso al contenido de un sitio web, ¿le da al Creador la oportunidad de calcular dicho acceso? Permite a los propietarios de dominio definir un precio fijo a pedido. Si un Crawler AI quiere extraer el contenido de este dominio, debe pagarlo. En el papel, esta herramienta tiene el potencial de cambiar el panorama actual, pero todo depende del alcance, la aceptación y las medidas que toman los operadores de rastreadores.
Imagen de portada | Imán feyissa
En Xataka | Le pregunté a la IA cada mierda y ahora estoy escribiendo un mensaje sobre ti.





{kind=link}